
O problema
Você roda ng test --coverage pela primeira vez num projeto Angular 21. O terminal pausa, diz que precisa instalar o pacote de cobertura, e te pergunta qual: @vitest/coverage-v8 ou @vitest/coverage-istanbul.
Você escolhe o default, segue a vida. Mas a pergunta em si não é trivial. Existem dois pacotes separados — com versões próprias, configurações próprias, hints de ignore próprios — porque eles fazem coisas fundamentalmente diferentes. Eles não são duas implementações do mesmo algoritmo. São duas estratégias completamente distintas para responder à mesma pergunta: quais partes do meu código foram executadas pelos testes?
A diferença entre as duas estratégias não é detalhe de implementação. Ela define como o relatório é construído, qual é o custo de gerar, em que ambientes funciona, e — por muito tempo — até quão preciso o resultado é. Entender essas duas estratégias muda como você lê o próprio número "82% de cobertura".
TL;DR
Existem duas formas de medir cobertura de código em JavaScript: instrumentação (reescrever o código-fonte para inserir contadores antes de ele rodar) e observação do runtime (pedir ao motor de JavaScript que reporte quais regiões de código ele executou). Istanbul implementa a primeira. V8 coverage implementa a segunda. Cada paradigma tem consequências distintas em precisão, velocidade, compatibilidade e no código que de fato roda durante os testes. Historicamente, Istanbul era mais preciso e V8 era mais rápido — um trade-off real. A partir do Vitest 3.2, o provider V8 passou a usar AST remapping e alcançou a mesma precisão do Istanbul, mantendo a velocidade. No Vitest 4, esse método se tornou o único. O folclore "V8 rápido, Istanbul preciso" deixou de valer para a maioria dos projetos.
Pré-requisitos
- Você já rodou testes com relatório de cobertura em algum momento (Jest, Karma com Istanbul, Vitest ou similar).
- Familiaridade básica com a ideia de AST (árvore sintática abstrata) e de source maps ajuda, mas não é obrigatória.
- O artigo assume Vitest como test runner. No Angular 21+, ele é o default.
Índice
- O que cobertura de código realmente mede
- Dois paradigmas para medir o mesmo fenômeno
- Como o Istanbul funciona: instrumentação antes da execução
- Como o V8 funciona: observação nativa do runtime
- Por que os relatórios divergiam historicamente
- O que mudou com o AST remapping no Vitest 3.2+
- Onde isso aparece no Angular 21+
- Trade-offs e quando escolher cada um
1. O que cobertura de código realmente mede
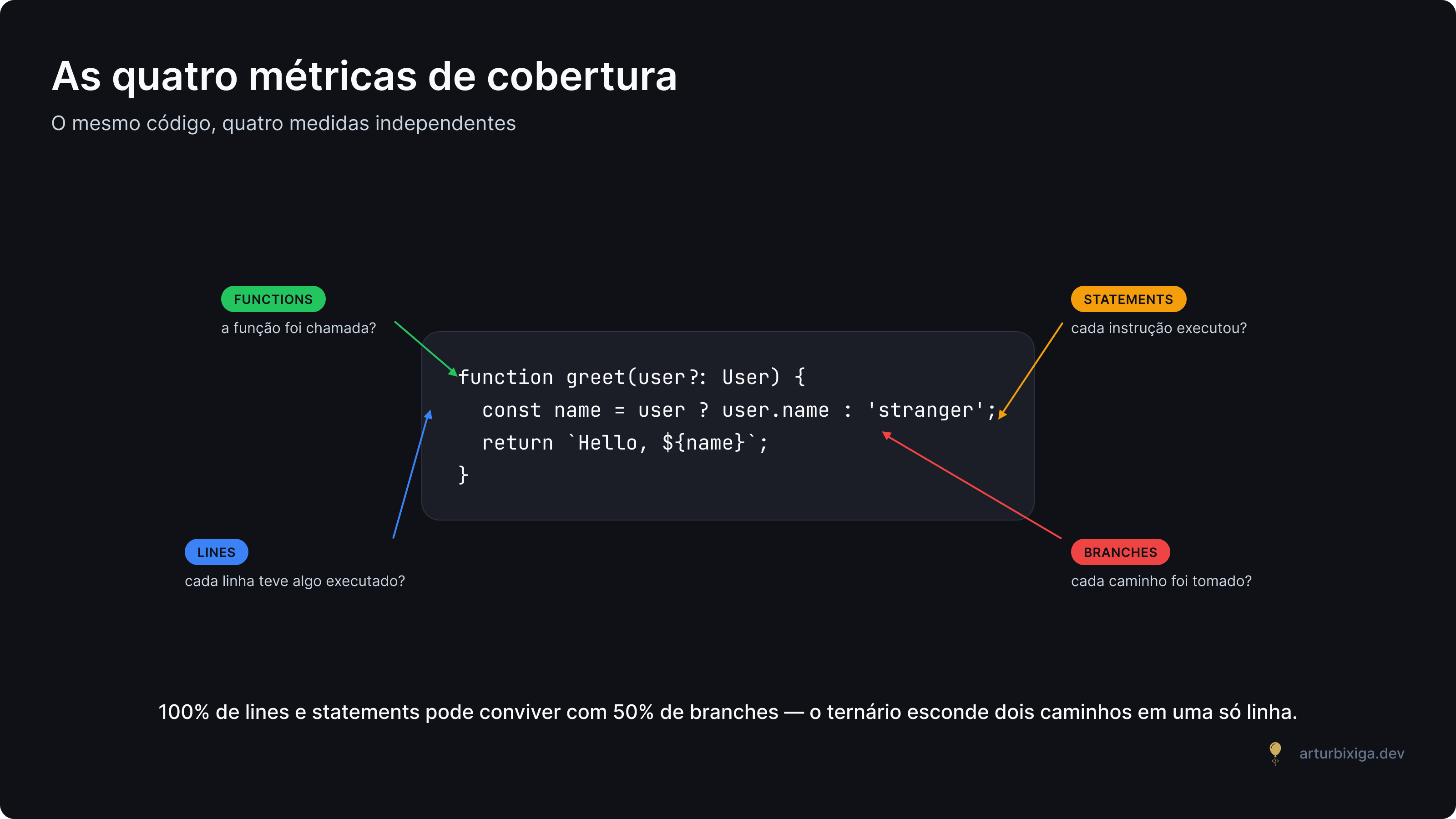
Antes de comparar ferramentas, vale ser preciso sobre o que elas medem. "Cobertura" não é um número único — é um conjunto de quatro métricas que costumam ser reportadas juntas, mas são conceitualmente distintas.
- Statements — cada instrução no código (uma atribuição, uma chamada de função, um
return) foi executada pelo menos uma vez durante os testes? - Branches — cada caminho possível numa decisão foi tomado? Para um
ifcomelse, são dois caminhos; para umswitchcom cinco cases, são cinco; para um?.(optional chaining), são dois (o valor existe ou não existe). - Functions — cada função declarada foi chamada pelo menos uma vez?
- Lines — cada linha do código-fonte teve pelo menos um statement executado?
Statements e lines parecem a mesma coisa, mas não são. Uma única linha pode conter múltiplos statements (const a = 1; const b = 2;). Um único statement pode ocupar várias linhas (uma chamada de função com argumentos quebrados em linhas separadas). Relatórios de cobertura costumam exibir por linha porque é o que o humano enxerga no editor — mas os contadores internos trabalham com statements.
A métrica mais estrita, e geralmente a mais reveladora, é branch coverage. Considere este código:
function greet(user?: User) {
const name = user ? user.name : 'stranger';
return `Hello, ${name}`;
}
Se o teste chama greet({ name: 'Ana' }), tanto line coverage quanto statement coverage reportam 100% — as duas linhas executam, e os dois statements (a atribuição de name e o return) também. Mas branch coverage reporta 50%: o operador ternário cria dois caminhos, e o teste só exercitou o caminho em que user é truthy. O caminho user falsy nunca foi tomado.
É diferente do que aconteceria se a função usasse if com dois returns separados. Nesse caso, o return do else nunca executaria, e line coverage também reportaria o problema — porque sobraria uma linha não executada. A versão com ternário é didaticamente mais clara justamente por isolar o efeito: toda a execução está nas mesmas duas linhas, e o único sinal do caminho não testado está em branch coverage.
Essa distinção importa porque, na prática, bugs vivem nos caminhos não tomados. Branch coverage captura esses casos mesmo quando o código-fonte comprime múltiplos caminhos em uma única linha; line coverage, não.
Qualquer ferramenta de cobertura, por baixo, precisa rastrear quando cada um desses elementos foi executado. É aí que os paradigmas divergem.
2. Dois paradigmas para medir o mesmo fenômeno
A pergunta de engenharia é direta: depois que o código rodou, como você sabe o que rodou?
Existem dois caminhos.
Paradigma A — Instrumentação pré-execução. Antes de executar o código, você modifica ele. Para cada statement, cada branch, cada função, você insere um contador. O código que roda nos testes não é o código que você escreveu — é uma versão expandida dele, com linhas adicionais que anotam o que está sendo tocado. Quando os testes terminam, você lê esses contadores e monta o relatório.
É como marcar cada árvore antes de atravessar a floresta. Na volta, você sabe exatamente por onde passou porque as marcas estão lá.
Paradigma B — Observação do runtime. Você não toca no código. Em vez disso, pede ao motor de execução — o V8, no caso de JavaScript rodando em Node ou Chrome — que reporte quais regiões de código foram executadas. O V8 já mantém essa informação internamente para otimizar a execução (decidir o que inlinar, o que compilar em código nativo, quais ramos são quentes). Tudo o que você precisa é expor esses dados.
É como percorrer a floresta com um GPS. As árvores continuam intocadas; o rastro é gerado pelo observador, não pelas marcas deixadas.

Cada paradigma tem consequências muito diferentes. Não são só implementações diferentes do mesmo resultado — são escolhas arquiteturais que determinam o que a ferramenta consegue fazer.
3. Como o Istanbul funciona: instrumentação antes da execução
Istanbul é a implementação canônica do paradigma A. Ele existe desde 2012 e, por mais de uma década, foi praticamente sinônimo de cobertura em JavaScript — ele alimenta o relatório que você via no Karma, no Jest por padrão, no nyc, na maioria das integrações de CI.
Por baixo, Istanbul é, antes de qualquer outra coisa, um transformador de código. Durante o build do projeto de testes, o plugin babel-plugin-istanbul (ou um equivalente) é adicionado à pipeline de compilação. Cada arquivo do projeto passa por uma transformação de AST. Para cada statement, cada branch, e cada função encontrada, o plugin insere um incremento em uma estrutura global — tradicionalmente chamada __coverage__.
O código que você escreve:
function classify(value: unknown) {
if (value == null) {
return 'empty';
}
return 'filled';
}
Vira, depois da instrumentação, algo conceitualmente parecido com isto (simplificado para legibilidade):
function classify(value) {
cov[file].f[0]++; // função classify foi chamada
cov[file].s[0]++; // statement 0: o if
if (value == null) {
cov[file].b[0][0]++; // branch: caminho "truthy"
cov[file].s[1]++; // statement 1
return 'empty';
}
cov[file].b[0][1]++; // branch: caminho "falsy"
cov[file].s[2]++; // statement 2
return 'filled';
}
Depois que os testes terminam, Istanbul lê essa estrutura global, agrega os números por arquivo, e gera o relatório — em texto, HTML, lcov, ou qualquer outro formato suportado.
Três consequências práticas desse design:
Precisão alta por construção. Os contadores estão exatamente onde o plugin decidiu colocá-los. Se você quer distinguir o caminho if do caminho else, basta um contador em cada. Se quer marcar branch coverage em um ?., basta descer no AST e cobrir os dois casos. A ferramenta tem controle total sobre a granularidade porque ela mesma escreve o código que conta.
Custo de build. Cada arquivo precisa ser transformado antes de rodar. Em projetos grandes, isso aparece. O próprio mantenedor do Istanbul estima a sobrecarga em torno de 3× comparado a rodar sem cobertura — uma penalidade de ~300%. Não é proibitivo, mas é perceptível em suítes grandes ou em CI com tempo limitado.
O código que roda não é o código que você escreveu. Isso às vezes tem efeitos colaterais sutis. Stack traces ficam menos legíveis. Perfil de performance durante os testes não reflete o que rodaria em produção. Debug de condições específicas pode ficar confuso quando você vê contadores aparecendo onde não esperava.
Independe do motor JS. Como a instrumentação acontece antes da execução, o código instrumentado é JavaScript normal. Ele roda em Node, em Chrome, em Firefox, em Safari, em jsdom, em happy-dom — em qualquer lugar que execute JavaScript. Istanbul não depende do V8.
4. Como o V8 funciona: observação nativa do runtime
O V8 coverage implementa o paradigma B aproveitando um recurso que o próprio motor já oferece: o Inspector Protocol.
O V8 é o motor JavaScript do Chrome e do Node.js. Internamente, ele já rastreia a execução do código — precisa disso para tomar decisões de otimização como JIT compilation, inline caching e branch prediction. Desde 2017, o V8 expõe parte dessas informações por um protocolo público — a mesma tecnologia que alimenta o DevTools do Chrome e o debugger do Node.
Para coletar cobertura, o Vitest (rodando em Node) faz, em essência, três chamadas:
// Antes dos testes
await session.post('Profiler.enable');
await session.post('Profiler.startPreciseCoverage', {
callCount: true,
detailed: true,
});
// Roda os testes normalmente, sem nenhuma modificação no código
// No fim
const { result } = await session.post('Profiler.takePreciseCoverage');
O que volta em result é um array de objetos — um por script carregado — contendo, para cada função compilada pelo V8, os ranges de bytes que foram executados e quantas vezes cada um. Não há transformação de AST. Não há contadores inseridos. O código que rodou é exatamente o código que o bundler gerou.
Quatro consequências práticas:
Velocidade alta. A coleta é quase um side effect da execução normal — o V8 já estava rastreando isso de qualquer forma. A sobrecarga típica fica em torno de 10%, uma ordem de grandeza menor que a do Istanbul.
Ranges de bytes, não statements. O V8 reporta em termos do código compilado, não do código-fonte. Ele diz "os bytes 120–145 executaram 3 vezes, 146–200 não executaram". Para transformar isso num relatório humano — "a linha 42 foi coberta" — é preciso aplicar source maps para voltar ao código original, e decidir como ranges se traduzem em statements e branches. Essa etapa de tradução é onde mora boa parte da complexidade.
Preso ao V8. O Inspector Protocol só existe no V8. Seus testes rodando em Node? Funciona. Rodando no Chromium via Playwright? Funciona. Rodando no Firefox (Gecko), no Safari (WebKit), ou no Bun (JavaScriptCore)? Não funciona. O provider V8 do Vitest simplesmente não consegue coletar nesses ambientes.
Dificuldade histórica com branches implícitos. Se o V8 nunca executou o corpo de um else — porque ele é implícito, ou porque a branch nunca foi tomada — ele não gera range algum para esse trecho. Saber que o else existia e que não foi coberto exige reconstruir o AST e confrontá-lo com os ranges recebidos. Durante muito tempo, essa reconstrução era aproximada.
5. Por que os relatórios divergiam historicamente
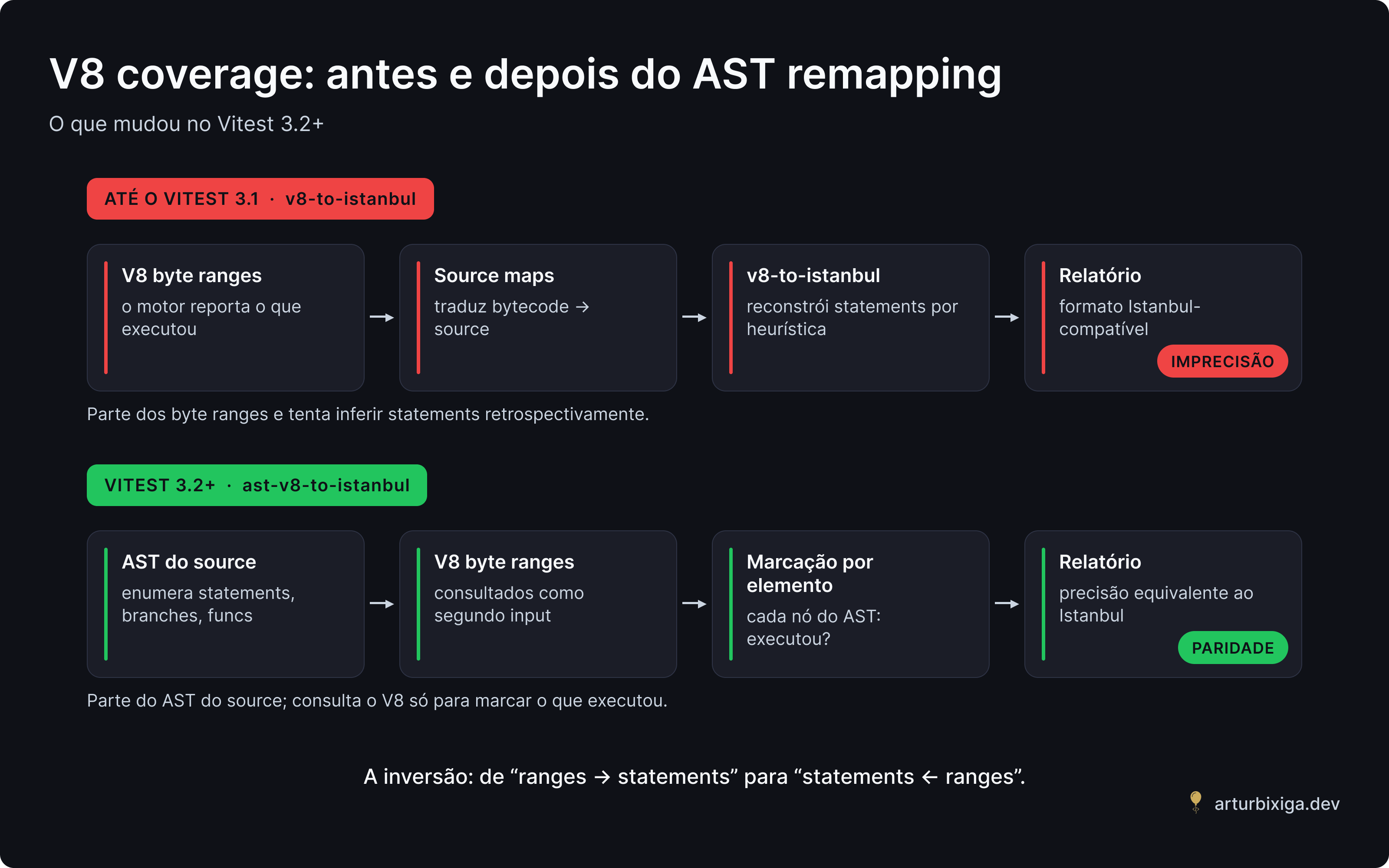
Durante anos, o Vitest (e o Jest, e ferramentas similares) convertiam dados do V8 em relatório Istanbul-compatível usando uma biblioteca chamada v8-to-istanbul. Ela pegava os byte ranges do V8, aplicava source maps para voltar ao código-fonte, e gerava uma estrutura compatível com os reporters do Istanbul.
Essa pipeline tinha dois problemas estruturais que geravam imprecisão em casos específicos.
Problema 1: precisão dos source maps. Source maps mapeiam posições do código compilado para posições do código-fonte. Funcionam bem em transformações simples, mas podem ficar imprecisos em transformações complexas — async/await desaçucarizado para state machines, classes com campos privados convertidos para WeakMaps, TypeScript com type erasure agressivo. Quando um byte range do V8 cai perto de uma fronteira mapeada de forma imperfeita, o relatório pode atribuir execução a linhas que não executaram, ou o inverso.
Problema 2: ranges não são statements. O V8 reporta "esse pedaço de código rodou". Statements e branches, porém, são conceitos do AST do código-fonte — não do bytecode que o V8 executa. Transformar um range de bytes em "o statement X foi executado" e "a branch Y foi tomada" exige reconstruir o AST e alinhar os dois mundos. O v8-to-istanbul fazia essa tradução heuristicamente, e as heurísticas falhavam em casos de borda.
O efeito prático mais conhecido: um if sem else podia aparecer com 100% de branch coverage mesmo sem teste para o caminho falso, porque o V8 simplesmente não reportava a ausência de execução no else implícito, e o v8-to-istanbul não tinha AST suficiente para inferir que o else existia. A discussão #7587 do Vitest documenta esse caso em detalhe.
Daí o folclore que circulou por anos: V8 é rápido mas impreciso, Istanbul é lento mas preciso. Durante muito tempo, foi uma descrição honesta dos trade-offs reais.
6. O que mudou com o AST remapping no Vitest 3.2+
A partir do Vitest 3.2, o provider V8 passou a usar uma abordagem diferente: AST-based remapping, implementada no pacote ast-v8-to-istanbul.
A ideia central é inverter a direção do raciocínio. Em vez de tratar os byte ranges do V8 como o sinal primário e tentar reconstruir statements a partir deles, o novo método parte do AST do código-fonte — exatamente como o Istanbul faria para instrumentar — e enumera cada statement, branch e função. Depois, consulta os dados do V8 para marcar cada elemento enumerado como executado ou não.
A diferença é sutil na descrição mas crítica no resultado. A enumeração dos elementos do AST é completa: todo else implícito está lá, todo ramo do ?. está lá, toda short-circuit de || está lá. Quando o V8 não reporta execução em algum deles, o AST remapping sabe exatamente o que isso significa — porque partiu do source, não do bytecode.
A documentação oficial do Vitest é explícita sobre a consequência: os relatórios do provider V8 passaram a ser idênticos aos do Istanbul. No Vitest 4, esse método deixou de ser opcional e se tornou o único suportado — a flag experimentalAstAwareRemapping foi removida porque agora é o comportamento padrão.
O trade-off que justificava escolher Istanbul por precisão simplesmente deixou de existir nos contextos onde o V8 funciona.
7. Onde isso aparece no Angular 21+
No Angular 21, o Vitest se tornou o runner de testes padrão, com um builder nativo — @angular/build:unit-test — que encapsula a configuração. O builder não expõe todas as opções do Vitest diretamente; para controlar detalhes como provider de coverage, você usa um arquivo de config do Vitest.
No angular.json, o target de teste aponta para o novo builder:
{
"projects": {
"meu-projeto": {
"architect": {
"test": {
"builder": "@angular/build:unit-test",
"options": {
"runner": "vitest"
}
}
}
}
}
}
Para configurar cobertura com controle fino, você cria um vitest.config.ts:
import { defineConfig } from 'vitest/config';
export default defineConfig({
test: {
coverage: {
provider: 'v8', // ou 'istanbul'
reporter: ['text', 'html'],
},
},
});
Ao rodar ng test --coverage pela primeira vez, o Vitest detecta que o pacote do provider não está instalado e pede para instalá-lo — seja @vitest/coverage-v8, seja @vitest/coverage-istanbul. Os dois pacotes são completamente independentes, com dependências próprias, versões próprias e, como vimos, hints de ignore próprios:
/* istanbul ignore next -- @preserve */
/* v8 ignore next -- @preserve */
Mudar de provider não é um ajuste de parâmetro: é trocar toda a estratégia de coleta. Os hints de um não funcionam no outro.
8. Trade-offs e quando escolher cada um
| Aspecto | Istanbul | V8 |
|---|---|---|
| Paradigma | Instrumentação pré-execução | Observação do runtime |
| Precisão de branches | Alta desde sempre | Alta a partir do Vitest 3.2+ |
| Sobrecarga típica (build + testes) | ~3× (≈300%) | ~1,1× (≈10%) |
| Ambientes suportados | Qualquer motor JS | Apenas V8 (Node, Chromium) |
| Código executado em teste | Reescrito com contadores | Original, intocado |
| Hints de ignore | /* istanbul ignore ... */ | /* v8 ignore ... */ |
| Pacote no Vitest | @vitest/coverage-istanbul | @vitest/coverage-v8 |
Istanbul faz sentido quando:
- Os testes rodam em um ambiente que não é V8 — Firefox via WebDriverIO, Safari/WebKit via Playwright, ou Bun.
- Sua pipeline de CI ou ferramentas de relatório dependem de particularidades da saída do Istanbul clássico que o V8 via Vitest ainda não reproduz com fidelidade (casos raros, mas existem).
- Você tem razões específicas para inspecionar o comportamento do código instrumentado em si.
V8 faz sentido quando:
- Os testes rodam em Node.js ou Chromium — que é o caso da esmagadora maioria dos projetos Angular.
- O tempo de execução dos testes importa, seja em CI ou em watch mode local.
- Você não tem nenhum motivo específico para preferir Istanbul.
Na prática, para um projeto Angular 21+ típico, o V8 é a escolha razoável por padrão. É o default do Vitest por um motivo: mais rápido, precisão equivalente, sem trade-off relevante para quem roda em Node.
Resumo e conclusão
Medir cobertura de código em JavaScript sempre se resumiu a duas abordagens arquiteturais distintas. Uma reescreve o código antes de executá-lo, inserindo contadores em cada ponto interessante — é o caminho do Istanbul, e foi o padrão de fato durante mais de uma década. A outra deixa o código intocado e pergunta ao motor de execução o que ele acabou de executar — é o caminho do V8 coverage, viabilizado pelo Inspector Protocol.
Cada paradigma carrega um conjunto de consequências que não são detalhes de implementação: são diferenças fundamentais em onde a informação nasce, em que ambientes cada abordagem funciona, qual o custo de coleta, e quão granular é o resultado. Durante boa parte da história dessas ferramentas, essas diferenças implicavam um trade-off concreto — velocidade contra precisão.
Esse trade-off está, para a maioria dos projetos, resolvido. O AST remapping introduzido no Vitest 3.2 permite ao provider V8 entregar relatórios com a mesma granularidade do Istanbul, sem abrir mão da velocidade. No Vitest 4, essa é a única forma suportada. Em um projeto Angular 21+ rodando em Node, o V8 é a escolha natural; Istanbul continua relevante principalmente onde o V8 não existe.
Mas a distinção conceitual vale além da escolha de provider. Cobertura é sempre um proxy — e o paradigma que produz o número importa para interpretá-lo. Uma linha "coberta" pelo Istanbul significa "existia um contador ali, e ele foi incrementado". Uma linha "coberta" pelo V8 significa "um range de bytes que mapeia para esta linha foi executado pelo menos uma vez". Os dois são úteis, mas nenhum é uma verdade absoluta sobre a qualidade dos testes. O número na tela é tão informativo quanto o modelo mental que você tem de onde ele veio.
Questões de compreensão
-
Um projeto tem uma função com
if (user) doWork(), semelse, e apenas um teste que chama essa função comuser = {}. Por que line coverage e branch coverage reportam números diferentes nesse caso? O que cada uma considera "coberto"? -
Descreva, em alto nível, o que o
babel-plugin-istanbulfaz com o código antes de ele rodar. Como uma função simples comoif (x) doA(); else doB();fica depois da instrumentação? -
Por que o provider V8 do Vitest não funciona quando os testes rodam no Firefox, mesmo com o Vitest instalado e configurado corretamente?
-
O que foi introduzido no Vitest 3.2 que invalidou a afirmação "Istanbul é mais preciso que V8 para branch coverage"? Qual a mudança técnica por trás dessa paridade?
-
Em que cenário concreto você ainda escolheria Istanbul deliberadamente num projeto novo, ciente de que vai pagar a sobrecarga de build?
Referências
- Vitest — Coverage Guide
- Vitest — Coverage Config
- Vitest — Migration Guide (v3 → v4)
- Istanbul — site oficial
- babel-plugin-istanbul — repositório
- V8 Blog — JavaScript Code Coverage
- Chrome DevTools Protocol — Profiler domain
- Angular — Testing Guide
- Angular — Migrating from Karma to Vitest
- Vitest Discussion #7587 — V8 vs Istanbul precision